


Governments need money: They have to pay salaries, build infrastructure, invest in research, pay their military, and so forth. In theory, they could use income from taxes to pay for such things. But in reality, revenues are often not quite enough to cover their expenses.
If you’re short on cash, then you can always take out a loan, right? Yes, but it’s often easier and cheaper to issue a bond — in the case of a country, what’s known as a “sovereign bond.” You say to the world, “Whoever wants to lend us $1,000, we’ll give it back to you in 10 years, and will pay you some annual interest, besides.”
A bond typically won’t give you a huge return on your investment — but it’s also very likely to be paid off, giving you a guaranteed return, but one that’s smaller than you might get with stocks. After all, a government isn’t going to stiff you, right?
Actually, some governments might well stiff you, what’s known as “defaulting.” To offset that chance, a government would have to give you a highest interest rate. Countries that have defaulted in the past, or whose political-economic situations aren’t looking too good, have to pay more interest. How much more? It depends on a number of factors, including the interest rate paid by their central bank, along with reports from various ratings agencies. A better rating means that a country can get away with paying less interest to its bondholders.

Data and six questions
This week, we looked at some data about the sovereign bond market, from the site "World Government Bonds" (https://www.worldgovernmentbonds.com/). This site tries to summarize the latest data about various countries’ bonds.
Here are my six questions, along with my detailed solutions; a link to my Jupyter notebook is at the bottom of this post.
Retrieve the per-country bond ratings from https://www.worldgovernmentbonds.com/world-credit-ratings/ into a data frame, in which the country name is the index, and the columns consist of the three main ratings agencies: S&P, Moody's, and Fitch.
Before doing anything else, I’m going to load Pandas into memory:
import pandas as pdWith that in place, what can I do next? There isn’t a CSV file that I can download, but the data does appear to be in an HTML table. My first thought was thus to use the “read_html” method to scrape the page and return a list of data frames, one for each table it finds. I thus wrote:
ratings_url = 'https://www.worldgovernmentbonds.com/world-credit-ratings/'
df = pd.read_html(ratings_url)Unfortunately, this failed. The reason? I got a “Forbidden” error, aka HTTP error 403, from the site. It would seem that the site doesn’t want people scraping its data, so anyone trying to read it in a programmatic way will be turned away.
Rather than give up, I decided to use another Python package, “requests”. The requests package provides us with a complete HTTP client, meaning that it’s basically a full-fledged browser inside of Python. Maybe requests wouldn’t set off any alarms? Let’s see:
import requests
r = requests.get(ratings_url)It worked! We got the content of the site back, in a response object. But how can we go from that object to parsing the HTML?
It turns out that read_html can be passed a URL, but it can also be passed a Python file-like object. Meaning, if I can somehow get the content into a file-like object (i.e., not necessarily a file, but something that implements the same API as files), then we will be able to pass the data to read_html.
The first step in doing so is to get the HTML content out of the response object. That’s easy; we can use “r.content”. But that content isn’t even returned as a string; rather, it’s returned as a “bytes” object. Fortunately, we can turn this bytes object into a string with the “decode” method.
But how can we turn a string into a file-like object? We can use the “StringIO” class, which comes with Python’s standard library and creates an in-memory object implementing the same API as a file.
In other words:
- We’ll get the response from the URL
- We’ll retrieve the bytes from that response
- We’ll turn the bytes into a Python string
- We’ll pass the Python string to a StringIO
- We’ll pass that StringIO to read_html
- read_html returns a list of data frames
- We’re interested in the first (and only) data frame, at index 0
- We retrieve the data frame at index 0, and assign it to ratings_df
Here’s what it looks like in code:
from io import StringIO
ratings_df = pd.read_html(StringIO(r.content.decode()))[0]Sure enough, ratings_df now contains the data from that site. Not too shabby! But I told you that we don’t need all of the columns, and that we should turn the countries into the index. So let’s do that:
ratings_df.columns = "Flag Country S&P Moody's Fitch DBRS".split()
ratings_df = ratings_df.drop(['Flag', 'DBRS'], axis='columns')
ratings_df = ratings_df.set_index('Country')On the first line, I replaced the column names that came from the Web page with shorter, easier-to-write names. I then removed two of them, using the “drop” method. Notice that I can pass a list of strings, rather than a single string, in order to drop multiple columns. Also, I have to specify that I’m dropping columns, rather than the default of rows.
Finally, I invoke “set_index” to use one of the existing column (“Country”) as the data frame’s new index.
In both the “drop” and “set_index” methods, Pandas returns a new data frame based on the original one. I could have used method chaining here, but decided that I would instead use plain ol’ assignment, because of the need to set the names of the columns.
At the end of all of this code, I have a data frame with three columns (one for each of the three ratings agencies), and whose index contains country names.
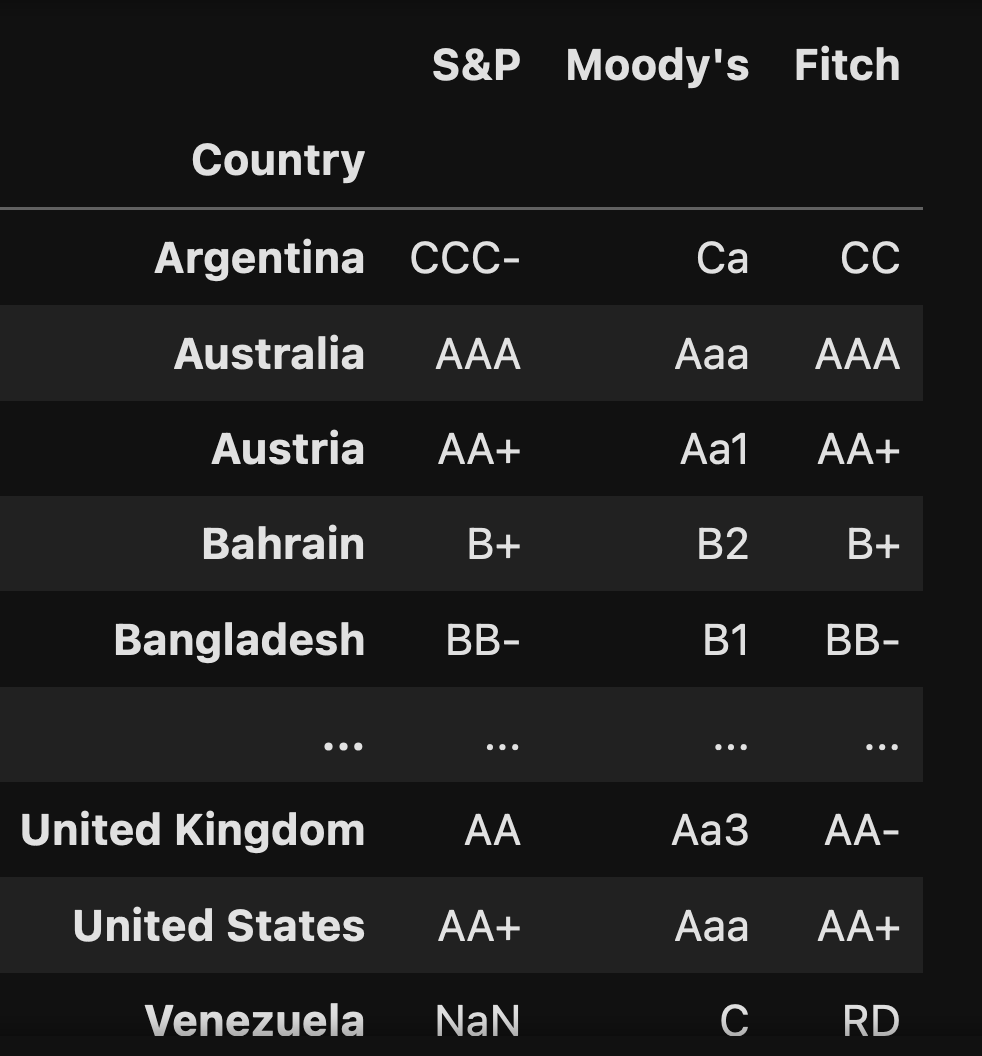
Which countries' bond ratings are all of the highest grade, namely AAA or Aaa?
Let’s say that you want the greatest assurance that your money will be safe, and you’re willing to take something of a hit on the yield (i.e., the interest you’ll earn). A good choice would be to invest in one of the countries that has gotten the highest rating (AAA or Aaa) from the bond ratings agencies.
So, what countries would those be?
There are a few ways that we could attack this. I decided to use the sneaky trick of treating True as 1 and False as 0. Normally, I tell people in my classes not to depend on this, since we’re fortunate to have real boolean types in Python — but in this case, ti really comes in handy.
My goal is to replace every AAA or Aaa rating with True, and every other rating with False. With that in place, I’ll then be able to count the number of True values in each row, and keep only those rows equal to 3.
First, I’ll need to find those rows in which every value is either AAA or Aaa. I decided to use “isin”, a data frame method:
(
ratings_df
.isin(['AAA', 'Aaa'])
)This returns a data frame whose index and columns are identical to ratings_df, but whose values are all True or False. Next, we’ll sum the data frame along its columns, giving us a series whose values are all integers — the result of summing True (1) and False (0) across each row:
(
ratings_df
.isin(['AAA', 'Aaa'])
.sum(axis='columns')
)This is the series that we get back:
Country
Argentina 0
Australia 3
Austria 0
Bahrain 0
Bangladesh 0
..
United Kingdom 0
United States 1
Venezuela 0
Vietnam 0
Zambia 0
Length: 74, dtype: int64Next, we want to keep only those rows that have a value of 3. For this, we’ll use “.loc” along with a lambda, indicating that we only want those rows with a value of 3:
(
ratings_df
.isin(['AAA', 'Aaa'])
.sum(axis='columns')
.loc[lambda s_: s_ == 3]
)Here’s what we get back:
Country
Australia 3
Denmark 3
Germany 3
Netherlands 3
Norway 3
Singapore 3
Sweden 3
Switzerland 3
dtype: int64We could stop there, but I thought it would be useful for us to just grab the country names, which we can do with “index”:
(
ratings_df
.isin(['AAA', 'Aaa'])
.sum(axis='columns')
.loc[lambda s_: s_ == 3]
.index
)The result is as follows:
Index(['Australia', 'Denmark', 'Germany', 'Netherlands', 'Norway', 'Singapore',
'Sweden', 'Switzerland'],
dtype='object', name='Country')We now know where it’s safest to invest our money.
But wait, where is the United States? As you might have heard, the US nearly hit its “debt ceiling” several times in the last few years. If it were to hit that ceiling, then it wouldn’t be able to borrow any more money. Which would mean not paying bondholders. Which, given the number of bonds out there, would be pretty catastrophically bad. The debt ceiling has always been raised, but the US has come perilously close to failing to do so. And so, while treasury bonds are still considered to be a very safe investment, and thus have low interest rates… but the US is no longer among the best-of-the-best in terms of ratings.