


Taylor Swift's Eras Tour (https://en.wikipedia.org/wiki/The_Eras_Tour) ended on December 8th. And while I'm not a Swiftie, I have long been fascinated and impressed by her business skills. She's obviously an enormously talented singer, songwriter, and all-around performer, but to earn $2 billion from a series of concerts, and cultivate millions of fans around the world reflects not just musical talent, but also impressive business sense.
The concerts, as I mentioned yesterday, were credited (or blamed) for numerous economic activity. The Federal Reserve noted that when Swift played in Philadelphia, it boosted the local economy. In Seattle, the crowd's jumping and dancing caused a minor earthquake. And indeed, in city after city around the world, hotels and Airbnb reservations sold out long in advance.
I thought that it might be fun to analyze some data about Swift's tour. I couldn't find any public data sets describing the number of tickets that were sold, or how much money was earned, other than the overall revenue of $2 billion I mentioned above. But I did find a list (on Wikipedia, of course) of the concerts and when they took place – and that's enough data for us to analyze and learn from.
Data and six questions
This week's data comes from the Wikipedia page about the Eras tour (https://en.wikipedia.org/wiki/The_Eras_Tour), which described (among other things) where and when each concert took place. I gave six questions for you to answer using Python and Pandas, based on that page.
As always, the Jupyter notebook that I used to solve these problems is at the bottom of the page.
Also: Subscribers to my Python+data subscription service (at https://LernerPython.com) are welcome to discuss each week's issue in the "Bamboo Weekly" section of our community Discord server.
Here are my solutions:
Create a data frame from the tables labeled "List of 2023 shows" and "List of 2024 shows" on the Wikipedia page (https://en.wikipedia.org/wiki/The_Eras_Tour). The data frame should have a "Date" column with the full date of each concert, as a datetime object. Remove footnotes from the "Date" and "City" columns. Drop the "Total" row, as well as the "Attendance" and "Revenue" columns.
First and foremost, let's load Pandas into memory:
import pandas as pdWith that out of the way, we now have to get two tables of data from the Wikipedia page into Pandas. Fortunately, Pandas comes with read_html, which scrapes a Web page and returns a list of data frames, one for each HTML table it encountered.
We can thus say:
url = 'https://en.wikipedia.org/wiki/The_Eras_Tour'
all_dfs = pd.read_html(url)
There isn't anything technically wrong with this. But we get back 12 HTML tables, in part because Wikipedia uses many HTML tables to structure its pages.
However, we can make things easier if we pass the match keyword argument to read_html. The value for this keyword argument is a regular expression (i.e., a string), describing text that must appear in any table that we want to retrieve. In our case, I only want the tables that match 'List of 202. shows', where . in a regular expression means, "match any character except for newline." I can thus say:
url = 'https://en.wikipedia.org/wiki/The_Eras_Tour'
df_2023, df_2024 = pd.read_html(url, match='List of 202. shows')
The call to read_html returns two data frames. I can assign them, using tuple unpacking, into two variables, df_2023 and df_2024. Each is a data frame with the information from the appropriate HTML table on the Wikipedia page.
However, this gives us two data frames, and we actually want only one. Plus, we have some cleaning up to do.
Let's start with the df_2023 data frame, with information from 2023 concerts. I first want to remove all of the footnotes from the data frame. I can do that with the replace method, which lets me perform a search-and-replace operation across all text in a data frame. Moreover, I can use a regular expression to describe what the footnote citation looks like. My code now looks like this:
(
df_2023
.replace(r'\s*\[\w+\]\s*', '', regex=True)
)The regular expression, which I wrote in a raw string to avoid warnings about backslashes, describes the following pattern of text:
- Zero or more whitespace characters,
\s* - A literal opening square bracket,
[ - One or more alphanumeric characters,
\w+ - A literal closing square bracket,
] - Zero or more whitespace characters,
\s*
In other words, I'm searching for text that looks like [a], perhaps with some whitespace before or after it. I want to remove it completely.
Next, we want to join this data frame with df_2024. In order to do that, the column names will have to match. We can handle that by renaming the column, using rename:
(
df_2023
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={'Date (2023)': 'Date'})
)Here, I passed rename the columns keyword argument, with a dict indicating the "from" and "to" strings I want to replace.
The next problem is a bit stickier: How can I turn the "Date" column, which contains strings, into datetime values? Normally, I could call pd.to_datetime, but the date needs to be in a known format. Plus, the dates in the first column don't contain the year – since each table contains concerts from a single year.
The solution is to use assign, which lets us create a new column on a data frame. We can use it to create a new column, but we can also use it to change an existing column, by assigning back to the same name. I can take the existing Date column, add '2023' to it, and then run pd.to_datetime on the result. Fortunately, the format MONTH DAY, YEAR is recognized automatically by pd.to_datetime, giving us the following code:
(
df_2023
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={'Date (2023)': 'Date'})
.assign(Date=lambda df_: pd.to_datetime(df_['Date'] + ', 2023'))
)We now have a version of df_2023 that we can combine with df_2024 – assuming it goes through a similar transformation. And indeed, we can do the following:
(
df_2024
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={'Date (2024)': 'Date'})
.assign(Date=lambda df_: pd.to_datetime(df_['Date'] + ', 2024'))
)However, this fails. Why? Because its final row includes the total amount of money brought in by the concerts, with a string ("Total") in the same column as we want for our dates.
However, we can apply a two-step solution: First, we can pass errors='coerce' to pd.to_datetime, which will give us NaT ("not a time," a variant on NaN) if it cannot convert. Then we can use dropna to remove any row that has NaN or NaT values:
(
df_2024
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={'Date (2024)': 'Date'})
.assign(Date=lambda df_: pd.to_datetime(df_['Date'] + ', 2024', errors='coerce'))
)Now we can put these transformations into a list, and pass it to pd.concat, which will create one data frame from the two of them:
(
pd
.concat(
[(
df_2023
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={'Date (2023)': 'Date'})
.assign(Date=lambda df_: pd.to_datetime(df_['Date'] + ', 2023'))
),
(
df_2024
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={'Date (2024)': 'Date'})
.assign(Date=lambda df_: pd.to_datetime(df_['Date'] + ', 2024', errors='coerce'))
)]
)This is fine, but we still need to remove the NaT and also some of the columns:
url = 'https://en.wikipedia.org/wiki/The_Eras_Tour'
df_2023, df_2024 = pd.read_html(url, match='List of 202. shows')
df = (
pd
.concat(
[(
df_2023
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={'Date (2023)': 'Date'})
.assign(Date=lambda df_: pd.to_datetime(df_['Date'] + ', 2023'))
),
(
df_2024
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={'Date (2024)': 'Date'})
.assign(Date=lambda df_: pd.to_datetime(df_['Date'] + ', 2024', errors='coerce'))
)]
)
.drop(columns=['Attendance', 'Revenue'])
.dropna()
)It works, giving us a data frame with 149 rows and five columns. The dtypes are all object (i.e., strings) except for Date, which is of type datetime. Success!
But... even after coming up with this, I found it a bit clunky. I'm repeating my query for each of the data frames, which makes the code less elegant, harder to read, and harder to maintain.
I would love to iterate over the data frames, but some of the transformations I'm doing require that I have not just the data frame, but the year of the data frame.
In other words, I could use a dictionary.
I'll create a dictionary whose keys are "2023" and "2024", and whose values are the data frames I got back from read_html. I can do that with zip, a buildin Python function that takes multiple iterables and returns an iterable of tuples. We can easily feed that to dict to get a new dictionary:
all_frames = dict(zip(['2023', '2024'],
pd.read_html(url, match='List of 202. shows')))
Then I'll use a list comprehension, iterating over the dict with dict.items, so that I get the key and value together. I can then pass the output list to pd.concat. Here's how that code looks:
df = (
pd.concat([(
one_frame
.replace(r'\s*\[\w+\]\s*', '', regex=True)
.rename(columns={f'Date ({year})': 'Date'})
.assign(Date=lambda df_: pd.to_datetime(df_['Date'] + f', {year}',
errors='coerce'))
)
for year, one_frame in all_frames.items()]
)
.drop(columns=['Attendance', 'Revenue'])
.dropna()
)
I now have all of the Eras Tour concerts in a single data frame. We can now start our analysis.
Create a bar plot showing how many concerts Swift performed in each month. Were there any months without performances?
We have a Date column containing datetime values, on which we can run groupby queries. But this question is a bit more subtle, asking for the number of concerts each month – including those where there were zero concerts.
This means that we'll need to use a slightly different tool, namely resample. This method is similar to groupby, but gives us the result of an aggregation method for every time period from the earliest to the latest in our data set. Even if there is zero data, we still get a result. We can even provide any time period we want, using a variety of date offset codes.
The problem is that resample only works when datetime values are in a data frame's index. We can fix that, though, by invoking set_index. Then we can invoke resample, using 1ME (i.e., the end of every 1-month period) on our data, invoking the count method:
(
df
.set_index('Date')
.resample('1ME')['City'].count()
This returns a series in which the index contains the final day of each month in our data set, and the values contains the number of Eras Tour concerts during that month:
Date
2023-03-31 5
2023-04-30 11
2023-05-31 12
2023-06-30 10
2023-07-31 9
2023-08-31 10
2023-09-30 0
2023-10-31 0
2023-11-30 9
2023-12-31 0
2024-01-31 0
2024-02-29 11
2024-03-31 6
2024-04-30 0
2024-05-31 11
2024-06-30 15
2024-07-31 14
2024-08-31 8
2024-09-30 0
2024-10-31 6
2024-11-30 9
2024-12-31 3
Freq: ME, Name: City, dtype: int64However, I asked not for textual output, but rather for a bar plot. We can get that with plot.bar:
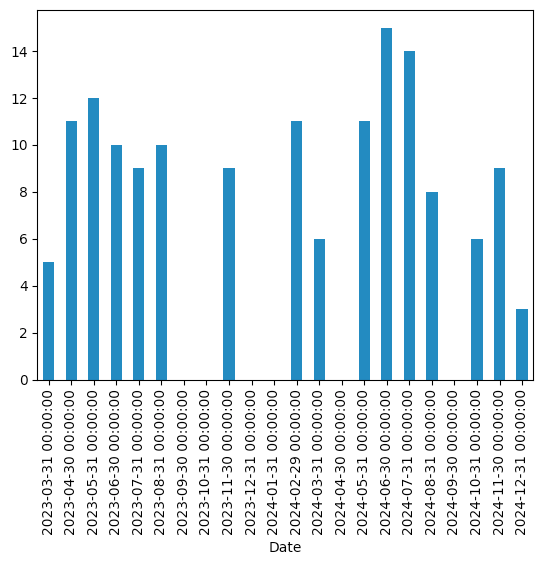
Were there any months without any concerts? Yes, indeed – September, October, and December of 2023, and January and April of 2024. But there were 15 concerts in June, and 14 in July – which basically means performing for hours on end every two days, on average.