


Housing — the lack of it, and the difficulty in finding an affordable home – has been a major issue in the US presidential election, which takes place in just under two weeks. It's an important enough issue that Kamala Harris has come out with a whole plan aimed at both increasing the supply of housing and reducing the price to first-time buyers. There are many different obstacles in the way of constructing new housing, as a recent episode of NPR's Planet Money from August (https://www.npr.org/2024/08/30/1197961522/minneapolis-minnesota-housing-2040-tim-walz) described.
This week, we're thus looking at data that the US Census Bureau has collected about the number of homes started and completed in each year, both for the United States in general and for each of four regions in the country.
Data and seven questions
This week's data comes from the US Census Bureau's "survey of construction." They offer a variety of data sets, all from this page:
https://www.census.gov/construction/nrc/data/series.html
We will look at two of the data sets from this page:
- Housing units started, https://www.census.gov/construction/nrc/xls/starts_cust.xlsx
- Housing units completed, https://www.census.gov/construction/nrc/xls/comps_cust.xlsx
Yesterday, I posed seven tasks and questions about the data. Here are my solutions; as always, a link to the Jupyter notebook I used to solve these problems is at the end of this post.
Create two data frames, one from each of the two Excel files references above, on the "Annual" tab in both files. The columns should be a two-level multi-index. Values labeled (NA) should be turned into NaN. Ignore the header and footer information. The index (rows) should contain the year from the first column.
Let's start things off by loading Pandas:
import pandas as pdNext, we'll use read_excel to read the Excel file for housing starts into a data frame:
starts_df = (
pd
.read_excel('starts_cust.xlsx')
)This doesn't quite work, for a variety of reasons:
- We need to pass the
sheet_namekeyword argument to get back a particular tab ("sheet") from the document - We want the "year" value to be our index, which we can specify with the
index_colkeyword argument, setting it to 0 to indicate that we want the first column - The headers are spread across two lines (4 and 5, using Pandas's zero-based indexing), so we can pass the
headerkeyword argument, giving it a value of[4,5], a list of integers. This has the added effect of ignoring the unstructured text before row 4. - There is some more unstructured text after the 65th row of data. We can thus pass the
nrowskeyword argument to grab only 65 lines into our data frame. - Finally, the Excel file uses
(NA)to indicate missing values, which we want to have the Pandas valueNaN. We can pass thena_valueskeyword argument, giving it a value of'(NA)', so that those inputs will be treated asNaN.
Putting this all together, we get the following:
starts_df = (
pd
.read_excel('starts_cust.xlsx',
header=[4,5],
sheet_name='Annual',
na_values='(NA)',
nrows=65,
index_col=0)
)The result is a data frame with 65 rows (but we knew that) and 12 columns.
We can do just about the same thing with the completed homes data:
comps_df = (
pd
.read_excel('comps_cust.xlsx',
header=[4,5],
sheet_name='Annual',
na_values='(NA)',
nrows=56,
index_col=0)
)The only real difference here is the number of rows, which reflects the fewer years of data. Indeed, we have 56 rows and (the same) 12 columns.
Create a line plot showing total housing starts and completions in the overall United States. Show starts with a dashed blue line, and completed houses with a solid red line. When did the most recent big changes in the housing market take place?
In order to create such a plot, we'll need to combine the data from the two different data frames we've created. But we don't want all of the data. We just need the "Total" values from the overall United States for each of the data frames.
Let's start by getting the total data for the United States from starts_df:
(
starts_df
[[('United States', 'Total')]]
)There are a few interesting aspects to the above code:
- Because we have a multi-index on our column names, we need to specify both the outer and inner levels in order to grab a particular column. We can do that with a tuple, naming the levels in order, from outside to inside. Note that you cannot use a list, because that would imply that we're trying to do fancy indexing, retrieving multiple columns.
- Normally, we could retrieve our column with a single set of square brackets. But that would return the column as a series. That's not inherently bad, except that we want to use this column as the left side on a "join" operation – and
joinis a method for data frames, not for series. By using double square brackets, we get back a data frame, albeit one with only a single column.
With that narrow data frame, we can invoke join to combine it with another data frame – the result of performing a similar operation on comps_df. Joining works on the index, so it's good (and not a coincidence!) that we already have the indexes set to the be the years in each data frame:
(
starts_df
[[('United States', 'Total')]]
.join(comps_df[('United States', 'Total')],
lsuffix='_starts', rsuffix='_comps')
)Notice that I passed the lsuffix and rsuffix keyword arguments to join. Whereas a data frame's index can have repeated values, the columns cannot. When we join two similar or identical data frames together, the resulting (new) data frame cannot have any repeated columns; we'll get an error message from Pandas. The lsuffix and rsuffix keyword arguments tell Pandas what strings to add to the column names that originated on the left and the right, so that the query can complete successfully.
Note that because comps_df has less data than starts_df, and because we performed the join using starts_df, the first few rows of the comps column contains NaN. That's not really an issue for us, but you will see a shorter line for completions.
Finally, we can create a line plot with plot.line. But I asked you to display the lines in a particular way, with a blue dashed line. If you pass the style keyword argument to plot.line, it is passed along to Matplotlib, which uses it to style the output. That style string should contain as many space-separated, three-character "words" as there are columns in the data frame, each of which specifies a color, a marker type, and a line type.
The full specification is here: https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html
In this case, I chose blue (b), dots (.), and a dashed line (:) for the first line, and a red line (r) with x markers (x) and a regular line (-):
(
starts_df
[[('United States', 'Total')]]
.join(comps_df[('United States', 'Total')],
lsuffix='_starts', rsuffix='_comps')
.plot.line(style='b.: rx-'.split())
)The result:
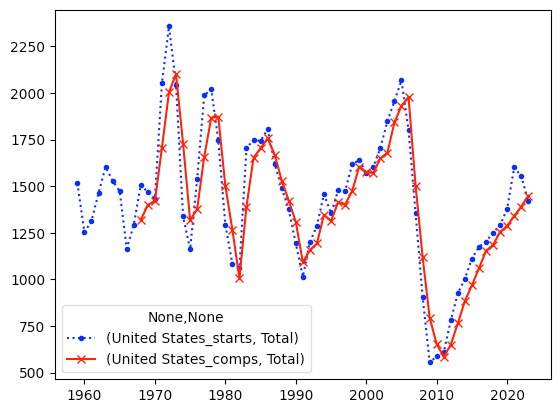
I asked when the most recent changes in housing starts and completions took place. There was a small drop in housing starts in 2020, and the US hasn't recovered from it. But even that peak was lower than what we see from about 2005, just before the 2008 housing crisis plunged US real estate into crisis. Indeed, I've heard numerous reports saying that oversupply of housing after that crisis led to low prices, which pushed home-construction companies out of the business. The US is still suffering from that period.