


[Administrative note: I'll be holding office hours for paid subscribers, including members of my Python+data membership program, on this coming Sunday, August 18th. Come with any and all Pandas questions; my goal is to answer anything I can. I'll send a reminder and Zoom link tomorrow.]
This week, we're looking at cyber attacks, which have been in the news quite a bit. The most prominent mentions have been Russian breakins into Microsoft's systems (https://edition.cnn.com/2024/03/08/tech/microsoft-russia-hack/index.html) and Iranian breaks into the Trump campaign (https://www.nytimes.com/2024/08/11/us/politics/trump-campaign-hacking-iran.html?unlocked_article_code=1.C04.wwrD.02yxkx89ZYzT&smid=url-share). Just yesterday, Politico reported that Google confirmed Iranian attempts to break into both the Biden (now Harris?) and Trump campaigns (https://www.politico.com/news/2024/08/14/google-iran-hackers-trump-biden-campaign-00174046).
Even when they aren't front-page headlines, such attacks take place all the time. And why not? They're easy and cheap to pull off, and can be hugely effective. I strongly recommend "The Perfect Weapon," the book by NY Times reporter David Sanger that opened my eyes to some of the issues on this topic.
Data and six questions
This week's data set comes from the Center for International and Security Studies at the University of Maryland (https://cissm.umd.edu/). They have a database of cyber attacks dating back to 2014. You can download it from here:
https://cissm.umd.edu/research-impact/publications/cyber-events-database-home
Click on the link "publication file" on the right side of the screen, and you'll get an Excel file containing their database.
This week, I have six tasks and questions for you. The learning goals include working with dates and times, grouping, pivot tables, plotting, and string methods.
As always, a link to download the Jupyter notebook I used to solve all six questions is at the bottom of the post.
Read the data into an Excel file. Make sure that the event_date column into a datetime dtype.
Before doing anything else, let's load Pandas:
import pandas as pdI then used read_excel to read the Excel file into a data frame:
filename = 'umspp-export-2024-07-19.xlsx'
df = pd.read_excel(filename)Normally, it wouldn't be an issue for event_date to be treated as a datetime value, because Excel has datetime columns, and those columns are usually read into Pandas with the appropriate dtype.
However, it would seem that the Excel column wasn't tagged as a datetime. For that reason, the dtype is seen as object, meaning a Python object – which normally means a Python string.
I decided that I should tell read_excel to parse the event_date column as a datetime, passing the column name (event_date) as an argument to parse_dates. For reasons I still don't quite understand, it didn't work. I was thus forced to do it manually, applying pd.to_datetime to the column, assigning it back to the event_date column:
df['event_date'] = pd.to_datetime(df['event_date'])The resulting data frame has 13,668 rows and 16 columns, each describing a cyber security event recorded by the CISSM.
Create a line plot showing the number of incidents in each month. Has the number of incidents grown consistently over time?
In order to plot the number of incidents each month, we'll need to count them. We can do that by running groupby on both the year and the month in the event_date column. (If we were to just group on the month, then we would know how many incidents occur in January vs. February vs. March, etc., across all years.)
We can group on multiple columns by passing a list of columns to groupby. And we can retrieve the year and month from a datetime column using the dt.year and dt.month accessors. Our query will thus look like this:
(
df
.groupby([df['event_date'].dt.year,
df['event_date'].dt.month])
['slug'].count()
)
Notice that I need to pick a column to count; in this case, I chose slug, but it really doesn't matter, so long as the column doesn't have any NaN values. The count method returns the number of non-NaN values for each combination of year and month. groupby sorts its results by default, meaning that the series we get back will be sorted chronologically, from earliest to latest year-month combinations.
To find out whether there has been an increase or decrease over time, we can then invoke pct_change, which tells us how much each month changed from the previous one. We can then sum those values, to find out the overall change from the start of the data set to the end:
(
df
.groupby([df['event_date'].dt.year,
df['event_date'].dt.month])
['slug'].count()
.pct_change()
.sum()
)
I get a 95% increase, meaning that it has nearly doubled in the decade during which CISSM has been tracking security incidents.
We can plot this by using plot.line on the result of the groupby:
(
df
.groupby([df['event_date'].dt.year,
df['event_date'].dt.month])
['slug'].count()
.plot.line()
)
I get the following plot:
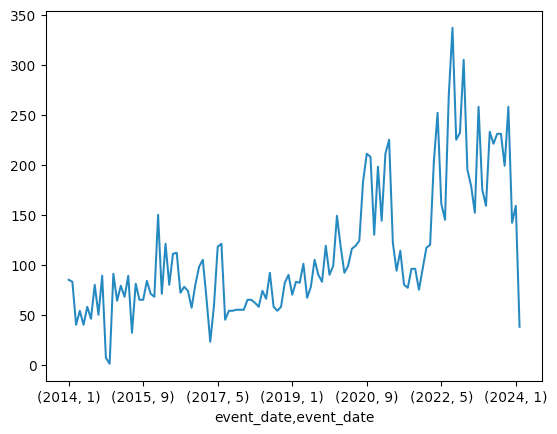
Notice that the number of incidents in 2024 appears to have plunged – but that doesn't mean we're doing well. Rather, it just reflects the fact that there were very few reports in the CISSM database so far, because it takes a while for things to be reported and then entered.