


[Are you at PyCon US? Come to my talk on Friday, “Dates and times in Pandas,” and also to my booth, where I’ll be giving away T-shirts and stickers, and raffling off free copies of Pandas Workout. If you’re at the conference, please come and say “hi”!]
This week — indeed, today — is the start of PyCon US 2024. It’s taking place in Pittsburgh, so I decided to look into some Pittsburgh-related data for this week’s challenges.
The data set I found is a log of calls made to the 311 non-emergency municipal phone number. Except that nowadays, you don’t have to call 311 on your telephone. (Really, who uses their phone any more for making calls?) You can access it via a Web site, an app, and a variety of other possibilities.
So we’ll learn a bit about what the people of Pittsburgh complain about, at least to their city government. And along the way, we’ll practice some data-analysis techniques in Pandas.

Shirts, flyers, and book giveaways — I’m all set for my PyCon booth!
If you want a more traditional Pittsburgh-related data set, by the way, there’s a classic one describing the city’s many bridges:
https://archive.ics.uci.edu/dataset/18/pittsburgh+bridges
Data and six questions
This week's questions are based on the 311 data. The home page for this data set is at
https://data.wprdc.org/dataset/311-data
This page includes links to the data and a data dictionary. It also says that the feed for this data was last working in December of 2022, and that they're working to restore it. So our data will only exist through 2022.
You can download the data from here:
https://tools.wprdc.org/downstream/76fda9d0-69be-4dd5-8108-0de7907fc5a4
Here are the challenges that I posed in yesterday’s message. As always, a link to the Jupyter notebook I used to solve these problems is at the end of the message.
Here are the questions I asked you to answer:
Read the 311 data into a data frame. Ensure that the "CREATED_ON" column is a datetime value.
First, I loaded up Pandas:
import pandas as pdWith that in place, I was then able to load the file that I had downloaded:
filename = '76fda9d0-69be-4dd5-8108-0de7907fc5a4.csv'
df = pd.read_csv(filename)The good news? This worked just fine, in the sense that the file uses commas (the default with “read_csv”), and the first line of the file contained column names.
However, by default, Pandas doesn’t look for or parse any date-related columns: It’ll identify integer and float columns, but anything other than that is treated as a string. One solution is to pass the “parse_dates” keyword argument to “read_csv”, telling it which column(s) to treat as datetime values:
df = pd.read_csv(filename,
parse_dates=['CREATED_ON']
)A second option is to use the PyArrow engine for reading CSV files. PyArrow is a new, cross-platform, cross-language data structure that will eventually replace NumPy as the back-end storage for Pandas. We can use its CSV-parsing mechanism, though, even if we still store the data in NumPy, by setting the “engine” keyword argument:
df = pd.read_csv(filename,
engine='pyarrow')This not only loads the CSV file faster than the default, but it has the advantage of identifying datetime columns and then setting their dtype appropriately. We can see this when we look at the “dtypes” attribute for our data frame:
_id int64
REQUEST_ID float64
CREATED_ON datetime64[s]
REQUEST_TYPE object
REQUEST_ORIGIN object
STATUS int64
DEPARTMENT object
NEIGHBORHOOD object
COUNCIL_DISTRICT float64
WARD float64
TRACT float64
PUBLIC_WORKS_DIVISION float64
PLI_DIVISION float64
POLICE_ZONE float64
FIRE_ZONE object
X float64
Y float64
GEO_ACCURACY object
dtype: objectSure enough, we see that the “CREATED_ON” column has a dtype of “datetime64[s]”. This is slightly different than what we would get with with “parse_dates”, which results in a dtype of “datetime64[ns]”, meaning with nanosecond granularity, but I think that we can do without such high accuracy in assessing when these calls arrive.
Create a stacked bar plot in which each bar represents the number of 311 requests in a given year. Each bar should show, via colorized sub-parts, the number of calls from each "REQUEST_ORIGIN". How do people submit most requests? Does this seems to be changing over time?
Normally, if we call “plot.bar” on a series, we get one bar for each element, labeled with the corresponding index. If we call “plot.bar” on a data frame, we get one cluster of bars for each index. Each cluster contains one bar for each column in the data frame. So in a 4-row, 3-column data frame, we would have 12 bars, clustered in to 4 groups of 3.
Let’s start with that as our goal. We’ll need a data frame in which the index contains the years in our data set, and the columns contain the unique values from REQUEST_ORIGIN. But we don’t want to get the mean or sum of these values; we just want to know how many times we saw each type of request per year.
The easiest way to create such a data frame is by running “pivot_table”:
- The index will be based on the years, which we can get with the “dt.year” on our datetime column, CREATED_ON
- The columns will be based on the values in REQUEST_ORIGIN
- The aggregation function wll be “count”
- It doesn’t matter much what column we use for values, so I’l just use REQUEST_ID.
We run the following code:
(
df
.pivot_table(index=df['CREATED_ON'].dt.year,
columns='REQUEST_ORIGIN',
aggfunc='count',
values='REQUEST_ID')
)This returns a data frame — a pivot table, no less — with 8 rows and 11 columns.
We can get a bar plot from this data by running “plot.bar”:
(
df
.pivot_table(index=df['CREATED_ON'].dt.year,
columns='REQUEST_ORIGIN',
aggfunc='count',
values='REQUEST_ID')
.plot.bar()
)This works, giving us a bar plot with one cluster per year and 11 bars per cluster:
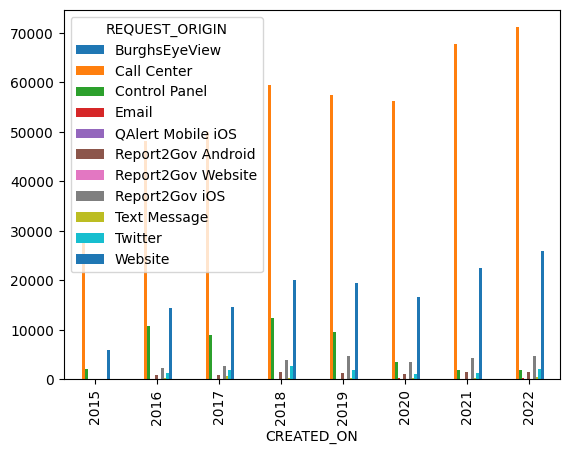
However, I asked you to create a stacked bar plot, one in which all of the bars for a given year are put on top of one another. With such a plot, we can compare total requests per year, and also the relative makeup of those requests:
(
df
.pivot_table(index=df['CREATED_ON'].dt.year,
columns='REQUEST_ORIGIN',
aggfunc='count',
values='REQUEST_ID')
.plot.bar(stacked=True, figsize=(10,10))
)Note that I made the size of the plot 10x10, in order for it to be more readable.
The result of the above query is:
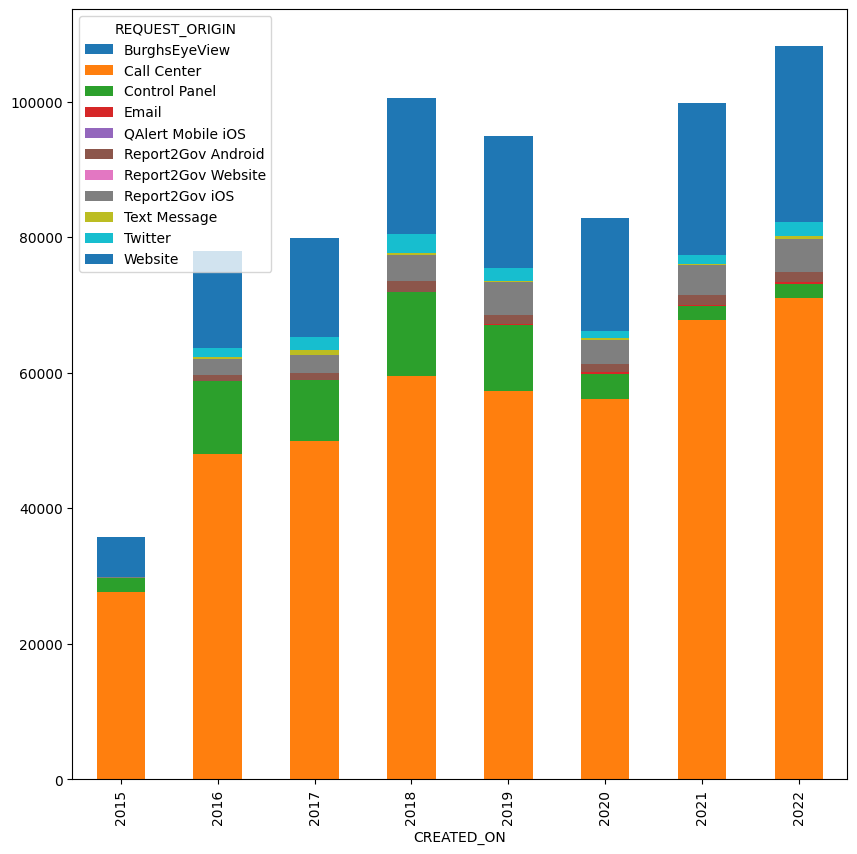
The chart shows that for all of the cynicism (including mine!) about how much people are using their phones to make actual calls, we can see here that the overwhelming majority of people contacting 311 are indeed calling that number.