


Inflation in the United States has been going down steadily over the last year. But that’s an overall measure; different parts of the economy will naturally rise and fall at different rates. A Washington Post article from earlier this week pointed to confusion regarding rental housing, and whether those prices are rising or declining — and at what rate that change is happening. (You can read the article at https://wapo.st/3SXVXEM .)
The confusion arises, in part, because landlords and tenants don’t have to submit prices to any central database. As a result, the government and researchers ask for individuals to cooperate, sharing rental prices with them on a regular basis. With a good sample and regular reporting, it should be possible to estimate the cost of rent. But it’ll just be a sample and an estimate — and different surveys, using different methods to sample the population, will almost certainly get different results.
I actually know a little bit about this from personal experience: When I was in graduate school just outside of Chicago, I was selected by the Bureau of Labor Statistics (BLS) to be one of their data points. Every few months, a researcher would call to ask how much we were paying in rent, and whether that had changed recently. The researcher was excited (as only a researcher can be) when my rent went up, and was disappointed when I told her that we were returning to Israel, and that I would no longer be able to provide her with data.
Data and six questions
This week, we looked at data from Apartment List, an online real-estate agency for rentals. Apartment List was cited in the Washington Post article as a data set showing different numbers than those used by the Bureau of Labor Statistics, and their data set is freely downloadable. I thought that it could provide us with some insights into rental costs — and also let us explore some Pandas features.
The data itself is downloadable as a CSV file from
https://www.apartmentlist.com/research/category/data-rent-estimates
Scroll to the bottom of the screen, and you'll be able to choose a research report to download. We'll use the "historic rent estimates, January 2017 - present.
There isn’t a data dictionary for this data set, but it does seem to be largely self documenting. The data provides information at several different levels of granularity, from national (i.e., the entire United States) to individual metropolitan areas. It also breaks the data down by the number of bedrooms in the rental unit, specifying 1, 2, or “overall.” (I’m not sure if the “overall” column includes the other two.)
Rental prices for each year-month combination is in a column whose name is in the format YYYY_MM, with a four-digit year and a two-digit month.
I gave you six tasks and questions this week. As always, a link to the Jupyter notebook I used to answer these questions is at the bottom of this newsletter.
Here are my solutions
Read the rent estimates into a data frame. Create a line plot showing the estimated rent in each month at the national level, with a separate line for each number of bedrooms (1, 2, and any).
The first thing to do, as usual, is load up Pandas:
import pandas as pdNext, we need to load the CSV file into a data frame using “read_csv”:
filename = 'Apartment_List_Rent_Estimates_2024_02.csv'
df = pd.read_csv(filename)In theory, I could have used the PyArrow engine to load the CSV file. But the file is so small that I decided it wouldn’t really make any difference.
The resulting data frame has 3405 rows and 94 columns. That’s a rather large number of columns, but it reflects the fact that we have many months’ worth of data, each of which is in a separate column.
Next, we have to trim down our data frame, keeping only those rows with national-level data. We can do that by filtering (using “loc”) the rows based on the “location_type” value:
(
df
.loc[df['location_type'] == 'National']
)This dramatically reduces the size of our data frame, returning only three rows — one for 1-bedroom apartments, another for 2-bedroom apartments, a third for “overall” number of bedrooms.
To get our data, I’ll need the “bed_size” (i.e., number of bedrooms) column and the data columns themselves, and nothing else. I’ll use the “filter” method to keep only those columns that match a particular pattern. In this case, the pattern will be a regular expression, saying that:
We want to start the match at the start of the string (^)
We want to look for either of these two patterns:
the string “bed_size”
four digits, _, and another two digits
The end of the pattern needs to match the end of the string ($)
(Confused by regular expressions? Check out my completely free e-mail course, “Regexp Crash Course,” at https://RegexpCrashCourse.com/ .)
This returns a new data frame, containing only the date columns and “bed_size”:
(
df
.loc[df['location_type'] == 'National']
.filter(regex=r'^bed_size|\d\d\d\d_\d\d$')
)I want to create a line plot in which the dates provide the X axis and the different bedroom counts are the Y axis. I’ll thus move the “bed_size” column into the index using “set_index”:
(
df
.loc[df['location_type'] == 'National']
.filter(regex=r'^bed_size|\d\d\d\d_\d\d$')
.set_index('bed_size')
)I’ll then transpose the data frame, turning the rows into columns and the columns into rows, using the “T” alias for the “transpose” method:
(
df
.loc[df['location_type'] == 'National']
.filter(regex=r'^bed_size|\d\d\d\d_\d\d$')
.set_index('bed_size')
.T
)Finally, I’ll invoke “plot.line”, which will use the index for the X axis and the columns for the Y axis. I asked Pandas to add grid lines to the plot, which makes it a bit easier to read:
(
df
.loc[df['location_type'] == 'National']
.filter(regex=r'^bed_size|\d\d\d\d_\d\d$')
.set_index('bed_size')
.T
.plot.line(grid=True)
)Here’s what I got:
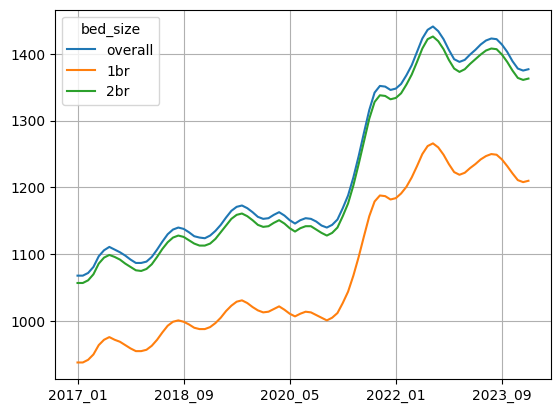
We can see that the rents really skyrocketed in 2021, and that they’ve bounced up and down a bit over the year and a half or so. And obviously, rents for 1-bedroom apartments are going to be lower than those for 2-bedroom apartments, but we do see very similarly shaped curves.
We can also see why people might feel like inflation is still rather high; since 2017, average rents have gone up by quite a lot. Most people aren’t going to look at the last part of the graph and say, “I see that rents are now staying stable, or even declining a bit.” Rather, they’ll compare their current rent with what they paid in 2017, and see a massive uptick.
Calculate, at a national level, the percentage change in rent from month to month. Create a line plot showing that percentage change.
The previous graph showed changes in the rents themselves. I now wanted you to calculate the percentage by which rents changed each month, and then plot that change.
The key to answering this question is the “pct_change” method, which returns a new data frame with an identical index and columns — but showing the percentage change that each value has from the value in the above row. (As a result, the first row has a NaN value.) By running this on the data frame after transposing it, we can graph the percentage change from month to month:
(
df
.loc[df['location_type'] == 'National']
.filter(regex=r'^bed_size|\d\d\d\d_\d\d$')
.set_index('bed_size')
.T
.pct_change()
.plot.line(grid=True)
)Here’s the resulting graph:
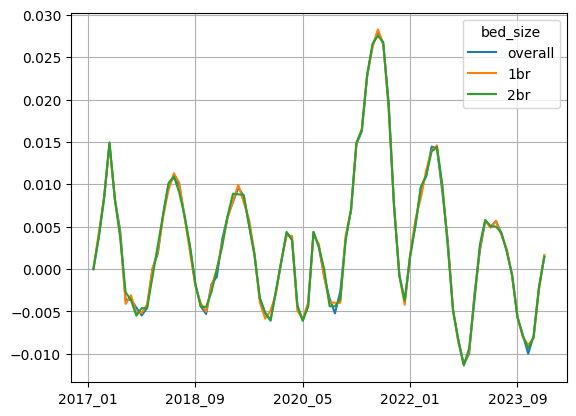
Wherever this graph has a value below 0, it means that the average national rent went down, relative to the previous month’s value. And wherever it’s above 0, it means that the average national rent increased from the previous month. The greater the value above 0, the greater the degree of increase.
We can see that in the last year, the average rent declined (i.e., was below 0) quite a bit of the time. But in the last few months, the graph has been ticking upward, becoming positive in just the last month or two — meaning that they’re now rising slowly, as opposed to falling slowly. By definition, this means that they are contributing to inflation. That doesn’t seem to contradict the story that we’re getting from the Fed and BLS, but it might be a more moderate view of that data. (Quite frankly, I’m still kicking myself a bit for not having downloaded and analyzed that data side-by-side with these values, seeing just how different they were from one another.)