


This week, we looked at the latest report from the New York Federal Reserve’s Household Debt and Credit Report. They produce this report every quarter, looking at the types of debt — car loans, student loans, mortgages, credit cards, and the like — and telling us how much debt Americans have taken on.
The NY Fed's HHDC report, including background information, is here:
https://www.newyorkfed.org/microeconomics/hhdc
You can download the specific report about household debt and credit as a nicely edited PDF file containing a large number of charts:
/content/files/medialibrary/Interactives/householdcredit/data/pdf/hhdc_2023q4.pdf
If you want to get a picture (no pun intended) of how much Americans are borrowing, and if they’re up to date with their payments, then this is a great report to read. But of course, here at Bamboo Weekly, we’re interested in the data itself, not in the charts that the Fed has worked so hard to produce.
Data and six questions
Fortunately, the NY Fed makes their raw data available in an Excel spreadsheet:
/content/files/medialibrary/interactives/householdcredit/data/xls/hhd_c_report_2023q4.xlsx
This document contains a very large number of sheets, alternating between the graphics found in the report and the data used to create those graphics. We’ll be looking at the data, reconstructing some of those reports.
You probably won’t need it, but a data dictionary describing the data is downloadable from:
/content/files/medialibrary/interactives/householdcredit/data/pdf/data_dictionary_hhdc.pdf
This week, I gave you six tasks and questions. Below are my solutions; as usual, a link to my Jupyter notebook follows the final answer.
Create a dictionary of data frames from the Excel spreadsheet; the keys should be the sheet names from the Excel file, and the values should be data frames containing the data. Only keep those with the word "Data" in their names. Make sure that each data frame's column names are taken from the sheet, and that the first column is turned into the index.
Before we do anything else, we’ll need to import Pandas:
import pandas as pdWith that out of the way, we’ll read the Excel file into Pandas using “read_excel”. It’s easy to think that Excel files are similar to CSV files, because they also contain rows and columns. But there are at least two differences:
- CSV files are text files. This means that Pandas needs to figure out what dtype to use for each column it reads from the file, or we can give it some hints. By contrast, data in Excel file is typed, no guessing needed. When you read data from Excel into Pandas, “read_excel” knows what dtype to assign to each column.
- An Excel document can contain one or more sheets, each of which is a spreadsheet in and of itself. If you use “read_excel” on a multi-sheet Excel document and don’t specify which sheet you want, you’ll get the first one. You can pass the “sheet_name” keyword argument to indicate that you want one or more other sheets (by passing the integer index of the sheet you want, the string name of the sheet you want, or a list of either integers or strings for multiple sheets).
We can load all of the sheets by passing None to “sheet_name”:
all_dfs = pd.read_excel(filename, sheet_name=None)Asking for multiple sheets returns a dictionary whose keys are the sheet names and whose values are data frames. I asked you to load all of the sheets with “Data” in their names. I’m not sure how “read_excel” did this, but it actually did most of the work we requested for us, ignoring the sheets containing the charts. We’ll filter through them more thoroughly in a moment.
I also asked you to ensure that the column names would come from Excel. Looking through the first few sheets, it seems like the column names are in Excel row 4. But of course, Excel uses 1-based indexing, whereas Python uses 0-based indexing. We thus indicate that Excel’s row 4 should be used for our headers by passing “header=3” to “read_excel”:
all_dfs = pd.read_excel(filename, sheet_name=None, header=3)Finally, I also asked you to use the first column (what Excel would call “A”) as the index to our data frame. We can do that most easily by using the numeric index:
all_dfs = pd.read_excel(filename, sheet_name=None, header=3, index_col=0)This is close to the end, but not quite: All of the dict keys in “all_dfs” are of the form “Page x Data” except for the first, called “TABLE OF CONTENTS”. We could remove it most easily by just removing that key-value pair with “del”:
del all_dfs["TABLE OF CONTENTS"]But I asked you to remove any key-value pair whose key doesn’t include the word “Data”. How can we accomplish that?

At first, it might seem like we can just iterate through the key-value pairs with a “for” loop, deleting any pair that doesn’t match our criteria:
for one_key in all_dfs:
if 'Data' not in one_key:
del all_dfs[one_key]However, if you try this, you’ll discover that it doesn’t work:
RuntimeError: dictionary changed size during iterationAs the exception says, you cannot modify a dict’s size while you’re iterating over it. (This is in contrast with lists, which do allow for that — although to be honest, it’s often a bad idea anyway.)
What we’ll do instead is iterate over a list that we create based on the keys. Because we’re iterating over the list, rather than over the dict itself, we can then remove whichever keys we want:
for one_key in list(all_dfs):
if 'Data' not in one_key:
del all_dfs[one_key]When we’re done, we only have the data-related sheets in our dict.
From the data frame describing the chart on page 3 of the report, create a stacked bar plot replicating that chart. Use the same colors as the NY Fed's chart. Show all of the index values (on the x axis), but rotate them 60 degrees, make the chart larger, and the font size smaller, so that all are visible.
The chart on page 3 shows a stacked bar plot, indicating the contribution that each type of debt adds to the overall US consumer debt picture. The index of that data frame represents quarters, in the format of “YY:QN”, using the final two digits of each year and numbers 1-4 for the quarters.
To get our data frame and retrieve just the columns we want, we can say:
(
all_dfs['Page 3 Data']
[['Mortgage', 'HE Revolving',
'Auto Loan', 'Credit Card', 'Student Loan', 'Other']]
)I should note that we’re fortunate the data was already sorted in chronological order, saving us from having to invoke “sort_index”.
If we want to create a bar plot, we can do that by invoking “plot.bar”. However, given that we have 84 rows and six columns, that would mean asking Pandas (and Matplotlib) to draw six bars at each of the 84 index points. Which
To avoid this, and also to get a more useful plot, I asked you to stack the bars. That means that instead of plotting the six values for each axis point next to one another, we’ll combine them together to get one tall bar. We’ll also be able to see how much each of these types of debt contributes to the overall picture in the US.
To do that, we can simply pass “stacked=True” to “plot.bar”:
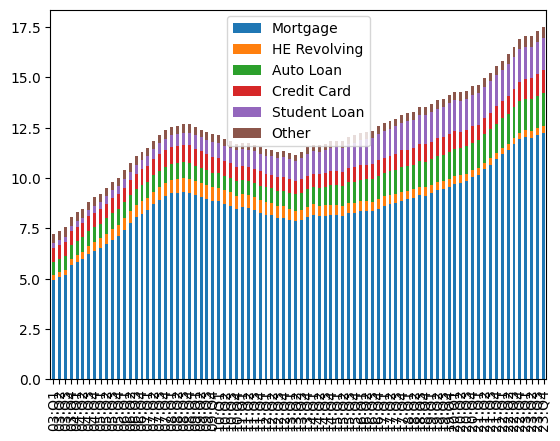
This is definitely better! But I decided to challenge you a bit further with this, to make it more readable, and to resemble the NY Fed’s chart.
I asked you:
- To make the figure bigger. We can do that by passing a two-dimensional tuple of integers to the “figsize” keyword argument.
- To reduce the font size of the x-axis labels. We can do that by passing an integer to the “fontsize” keyword argument.
- To rotate the x-axis labels to 60 degrees. We can do that by passing 60 to the “rot” keyword argument.
- Finally, I asked you to set the colors as was done by the NY Fed. We can do that by passing the “color” (yes, singular!) keyword argument, along with a list of color names.
The resulting query is:
(
all_dfs['Page 3 Data']
[['Mortgage', 'HE Revolving',
'Auto Loan', 'Credit Card', 'Student Loan', 'Other']]
.plot.bar(stacked=True, rot=60, figsize=(8, 8), fontsize=5,
color=['darkorange', 'purple', 'green',
'blue', 'red', 'gray'])
)And the resulting plot:
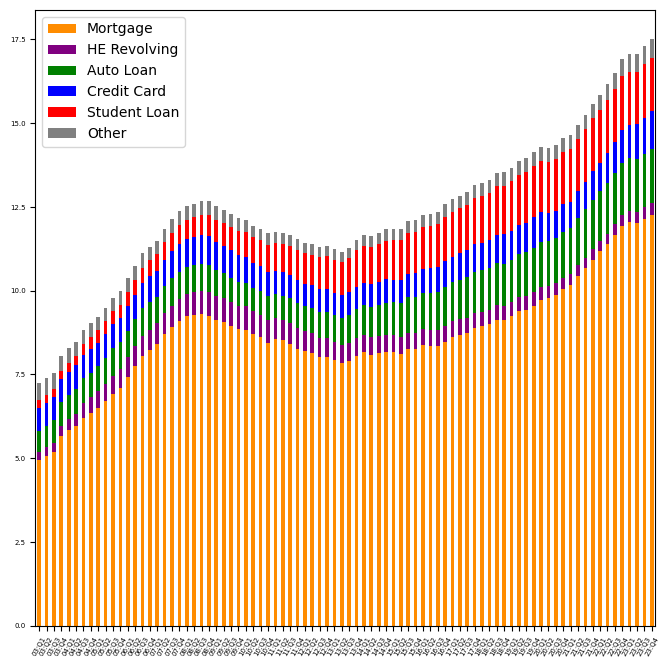
And yes, it’s still hard to read the labels at this size (in the newsletter), but I promise that they’re more readable than before.
We can see that the bulk of American debt is in mortgages, with auto loans and student loans far behind. Moreover, we can see that overall debt has been rising in the last decade, after dropping between 2008 and 2013 — the “Great Recession,” as it is sometimes known, and its aftermath.
I was honestly expecting to see credit-card debt be a much larger part of American debt, but it makes sense that paying for a house, car, or university education will always be more than someone’s credit-card limit.