


This week, we looked at data describing the movement of ships near and through the Red Sea. The Houthi rebels in Yemen recently threatened and attacked ships entering the Red Sea via Bab el Mandeb, the "Strait of Tears” that I marked with a red dot on the below map. They are doing this in solidarity with Hamas, which killed and kidnapped hundreds of Israelis on October 7th, and which is now at war with Israel in the wake of those attacks. The threatened ships are typically on their way to or from Egypt’s Suez Canal, marked with a purple dot on the map below.
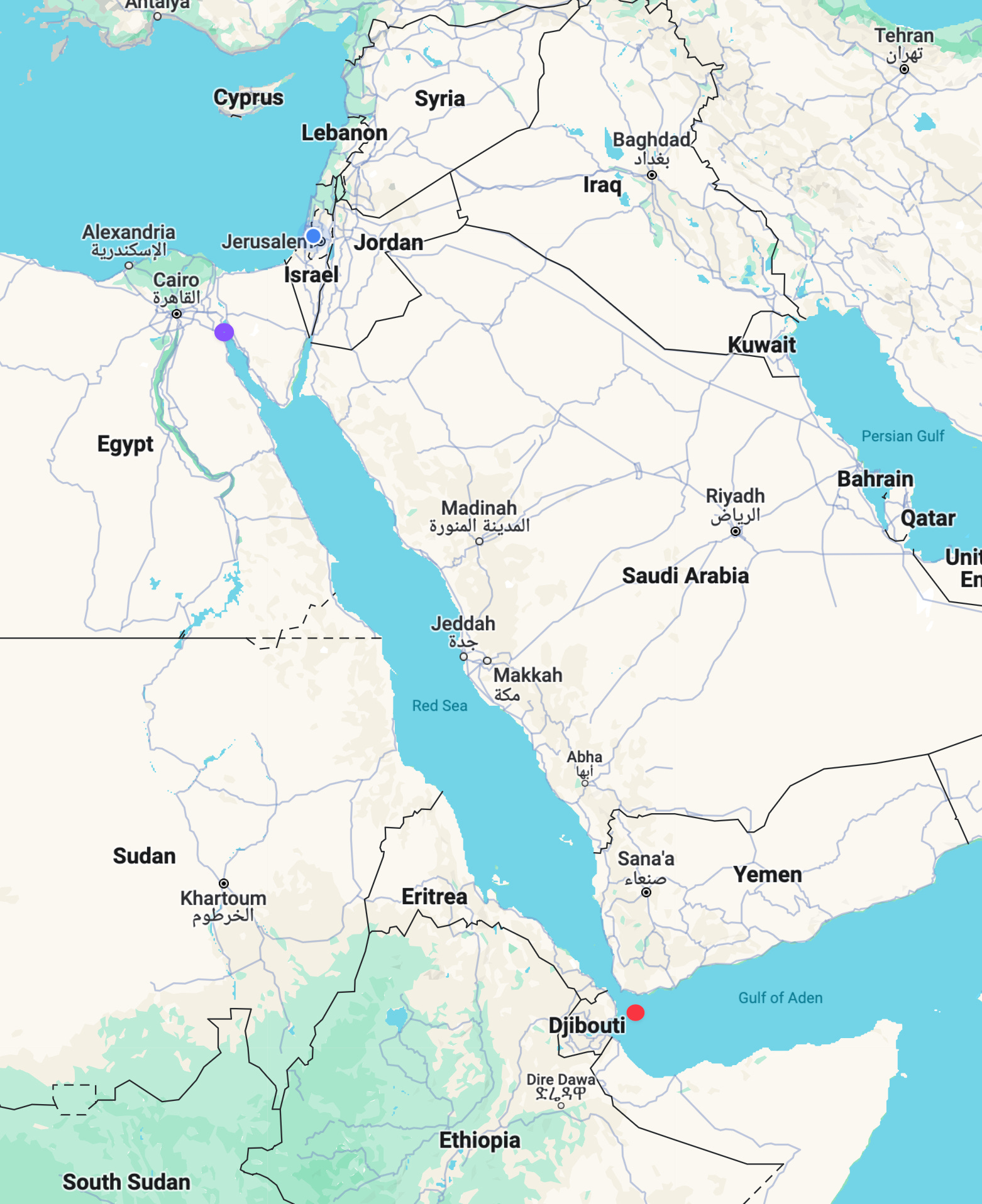
A huge proportion of the world’s goods pass through the Suez Canal. Given the greater risk that ships face when passing through that area, I’ve read and heard that companies have changed their routes to go around South Africa’s Cape of Good Hope. Needless to say, makes for a longer and more expensive journey. The Houthis’ actions have the potential to raise prices food goods around the world.
Data and seven questions
This week, we looked at data from PortWatch (https://portwatch.imf.org/), a joint project between the International Monetary Fund and the University of Oxford. They are using a variety of sources, including satellite trackers, to count the number of ships that pass through numerous ports around the world. Because of the situation at the Red Sea, they have created a special page (https://portwatch.imf.org/pages/573013af3b6545deaeb50ed1cbaf9444) describing and depicting the number of ships passing through Bab el Mandeb, the Suez Canal, and the Cape of Good Hope.
I asked you to download the CSV files associated with those three data points. On my computer, they were named:
- bab-el-mandeb-strait-dai.csv
- suez-canal-daily-transit.csv
- cape-of-good-hope-daily.csv
Based on these three files, I asked seven question; as always, a link to the Jupyter notebook that I used to solve the problems is at the bottom of this issue.
Create a dictionary of data frames, in which the keys are short (3-5 letter) nickname for the data source, and the values are data frames, one for each of the three CSV files. In each data frame, the original "DateTime" column should be the index, and parsed as a "datetime" dtype. Keep only the "Number of Cargo Ships" and "Number of Tanker Ships" columns, renamed to something shorter.
Before doing anything else, I loaded up Pandas:
import pandas as pdWe can always load a CSV file into Pandas with “read_csv”. If we have to load several CSV files into a single data frame, then we can often do so with a combination of a list comprehension and “pd.concat”.
But here, things are a bit different: I want to merge the data from each CSV file into a single data frame, but each file contains parallel data, with identical column names.
Here’s how I did it:
First, I created a dict whose keys were strings, the nickname that I assigned to each data set. The values of that dict were the filenames from which I was going to read the data. Note that I didn’t repeat the “.csv” extension, since I can add that later:
all_filenames = {'mandeb': 'bab-el-mandeb-strait-dai',
'suez': 'suez-canal-daily-transit',
'gh': 'cape-of-good-hope-daily'}
I wanted to create a second dict, one whose keys would be identical to all_filenames, but whose values would be data frames based on those filenames. Since I have an iterable (a dict) and I want to create a new dict based on it, I decided that a dict comprehension would be a good way to go:
all_dfs = {
key :
pd.read_csv(os.path.join('/Users/reuven/Downloads',
f'{filename}.csv'))
for key, filename in all_filenames.items()
}The above dict comprehension iterates over all_filenames using the “dict.items” method, giving us each key-value pair from all_filenames, one at a time.
I took the key, and used it (as is) for the key in the output dict. Because the filenames were all in my “Downloads” directory, I used “os.path.join” to produce a filename based on its arguments. It’s here, as you can see, that I added the “.csv” extension to each filename.
The good news is that the above code works, giving me a dict of data frames. But there were a few more things that I had to do in order to get it into shape:
First, I wanted to change the names of the columns to something shorter. The good news is that each file named the columns identically, giving us some consistency. The bad news is that you cannot have identically names columns in a data frame. As a result, I decided to rename the columns not only to be shorter, but to guarantee uniqueness. I could do this with the “names” keyword argument for read_csv:
all_dfs = {
key :
pd.read_csv(os.path.join('/Users/reuven/Downloads',
f'{filename}.csv'),
names=['date', f'cargo_{key}', f'tanker_{key}'])
for key, filename in all_filenames.items()
}However, the above code won’t work. That’s because I’ve only given names to three of the five columns in the file. I can select which columns are loaded using the “usecols” keyword argument. But because I’ve given alternative names to the columns, I’ll have to refer to them by integer indexes. Moreover, I’ll have to tell Pandas that the columns are given names on the first row (i.e., row index 0) of each file, but that we should ignore that row:
all_dfs = {
key :
pd.read_csv(os.path.join('/Users/reuven/Downloads',
f'{filename}.csv'),
usecols=[0, 1, 2],
names=['date', f'cargo_{key}', f'tanker_{key}'],
header=0)
for key, filename in all_filenames.items()
}Notice that I used f-strings to set the names. Students in my courses often believe that f-strings are always used along with the “print” function, but I tell them that actually, we can use them to define strings anywhere in a program. This is one example of where they’re useful beyond printing.
Finally, I asked you to have Pandas parse the date column as a “datetime” dtype, which we can do via the “parse_dates” keyword argument to read_csv. Plus, I asked you to make it the index, which we can do with the “index_col” keyword argument to read_csv.
In the end, I managed to create this dict of data frames as follows:
all_dfs = {
key :
pd.read_csv(os.path.join('/Users/reuven/Downloads',
f'{filename}.csv'),
parse_dates=[0],
usecols=[0, 1, 2],
names=['date', f'cargo_{key}', f'tanker_{key}'],
header=0,
index_col=0)
for key, filename in all_filenames.items()
}Could I have created a list, rather than a dictionary? Yes, in this case, that would have been just fine. However, I found it a bit easier to manage and work with as a dict, rather than a list.
Join these three data frames together into a single data frame with six columns (two from each of the original data frames).
With this dict in place, I wanted to join them together into a single data frame.
As I mentioned above, the easiest way to combine several data frames into a single one is with pd.concat, to which you pass an iterable of data frames as an argument. The data frames are joined, top to bottom, and you end up with one, large data frame.
In our case, though, we don’t want to stack them top to bottom. Rather, we want to stack them side-to-side, such that we get a new data frame with six columns, two from each of the original ones.
Instead of passing the entire “all_dfs” dictionary to pd.concat, we’ll just pass the values from the dict. When you invoke the “dict.values” method, you get a special type of object that uniquely used for dict values. But for our purposes, that doesn’t matter, because it’s iterable, and we can thus pass it to pd.concat.
To tell pd.concat that we want to concatenate them sideways, rather than top-to-bottom, we pass the axis=“columns” keyword argument to pd.concat:
df = pd.concat(all_dfs.values(), axis='columns')The result of calling pd.concat is a new data frame, which we assign to the variable “df”.
We’re now ready to get started analyzing the data!