


WeWork just filed for bankruptcy, and given the huge amount of press and attention that they got over the years — including numerous books (https://www.amazon.com/Cult-We-Neumann-Startup-Delusion-ebook/dp/B08FHC77MT), podcasts (https://wondery.com/shows/we-crashed/), and articles — I thought that it would be worth looking at them, and some data related to them.
I was interested in finding data about commercial real estate and office space, but wasn’t able to find any that was freely available and downloadable. However, I did find some data sources about WeWork’s stock price, as well as the S&P 500 stock index, the state of the office-construction market, and the office-rental market. Let’s see what we can find and understand about WeWork and associcated data. And along the way, we’ll have fun with Pandas!

Data and seven questions
This week, we looked at four different data sources:
- WeWork stock information, which I downloaded from Yahoo Finance: I went to https://finance.yahoo.com/quote/WE/history, asked for the "max" time period, and then clicked on "download," which put downloaded a CSV file (WE.csv) to my computer.
- The S&P 500 index -- or actually, a proxy for it, since I cannot seem to download the S&P 500 directly from Yahoo. I went to https://finance.yahoo.com/quote/SPY/history, chose the "5 year" time period, clicked on "apply," and then downloaded the CSV file (SPY.csv) to my computer.
- From FRED, the amazing data portal at the St. Louis Fed, I downloaded data about spending on office construction in the US. The page is at https://fred.stlouisfed.org/series/TLOFCONS, and I retrieved the CSV file by clicking on "download" and choosing CSV. You could also decide to download the data directly via the URL.
- Also from FRED, I downloaded data about office rents in the US. The page for that data is at https://fred.stlouisfed.org/series/WPU43110101, and I (again) retrieved the CSV file by clicking on "download" and chosing CSV. You could, as before, also decide to download the data directly via the URL.
Given this data, I gave you seven different tasks and questions. A link to the Jupyter notebook I used to solve these problems follows the questions and solutions.
Create a data frame for each of the four CSV files, parsing the date columns and using them as indexes.
Before doing anything else, I made sure to import the Pandas library:
import pandas as pdWith that in place, I was able to create four data frames, one from each of the CSV files that I had downloaded. I started with the WeWork data, and ran “read_csv” on it:
we_df = pd.read_csv('WE.csv')This worked, but wasn’t quite what I wanted. I did ask, after all, to ensure that the date would be the data frame’s index, and that it would have datetime information, rather than be text strings. The dates are in a format that is easy to parse, but we still need to specify that Pandas should do so (“parse_dates”) and that the column should be the index (“index_col”):
we_df = pd.read_csv('WE.csv',
index_col='Date',
parse_dates=['Date'])With this in place, my data frame had a datetime index, plus six columns: The opening and closing prices for each day, the high and low prices for each day, the adjusted closing price, and the volume.
What about the S&P 500 data? I used almost precisely the same code:
spy_df = pd.read_csv('SPY.csv',
index_col='Date',
parse_dates=['Date'])It shouldn’t be a huge surprise that these two data sets could be treated similarly, because they both come from Yahoo Finance.
What about the data about office-construction spending? Here, I decided to do a few things differently than with the Yahoo-based files:
- First, I decided to give the URL to “read_csv”, downloading the file directly from the source, rather than saving it to disk and then loading it. Yahoo Finance didn’t allow me to do this, but FRED does, so I’ll enjoy taking advantage of it.
- Second, I decided to give more reasonable names to the columns than FRED did. This meant using the “names” keyword argument to give names, but that also meant telling “read_csv” to ignore the existing header row. It also meant indicating which column was a date, and which should be used as the index, by specifying the column number — because until we actually create the data frame, the column names won’t exist.
The query ends up looking like this:
construction_spending_df = pd.read_csv('https://fred.stlouisfed.org/graph/fredgraph.csv?bgcolor=%23e1e9f0&chart_type=line&drp=0&fo=open%20sans&graph_bgcolor=%23ffffff&height=450&mode=fred&recession_bars=on&txtcolor=%23444444&ts=12&tts=12&width=1318&nt=0&thu=0&trc=0&show_legend=yes&show_axis_titles=yes&show_tooltip=yes&id=TLOFCONS&scale=left&cosd=2002-01-01&coed=2023-09-01&line_color=%234572a7&link_values=false&line_style=solid&mark_type=none&mw=3&lw=2&ost=-99999&oet=99999&mma=0&fml=a&fq=Monthly&fam=avg&fgst=lin&fgsnd=2020-02-01&line_index=1&transformation=lin&vintage_date=2023-11-08&revision_date=2023-11-08&nd=2002-01-01',
parse_dates=[0],
index_col=0,
header=0,
names=['Date', 'spending'])Yeah, that URL is pretty ridiculous and long; I copied it from the “CSV download” option in the “download” menu on FRED. But it worked, giving me a data frame with a datetime index and a single column of data.
Finally, I downloaded the FRED data for office rents in the US, passing the same options as before:
gross_rents_df = pd.read_csv('https://fred.stlouisfed.org/graph/fredgraph.csv?bgcolor=%23e1e9f0&chart_type=line&drp=0&fo=open%20sans&graph_bgcolor=%23ffffff&height=450&mode=fred&recession_bars=on&txtcolor=%23444444&ts=12&tts=12&width=1318&nt=0&thu=0&trc=0&show_legend=yes&show_axis_titles=yes&show_tooltip=yes&id=WPU43110101&scale=left&cosd=2008-12-01&coed=2023-09-01&line_color=%234572a7&link_values=false&line_style=solid&mark_type=none&mw=3&lw=2&ost=-99999&oet=99999&mma=0&fml=a&fq=Monthly&fam=avg&fgst=lin&fgsnd=2020-02-01&line_index=1&transformation=lin&vintage_date=2023-11-08&revision_date=2023-11-08&nd=2008-12-01',
parse_dates=[0],
index_col=0,
header=0,
names=['Date', 'rents'])We now have four data frames, all with datetime values in their indexes, and with 1-6 rows of data that we can use in our analysis.
Get a new version of the WeWork data, in which each row represents the mean values from that month.
My plan is to join these data frames together, in order to compare them on particular dates, However, the WeWork stock price is reported daily, whereas the FRED data is reported monthly. We somehow need to get things to match up.
The way that I want to do that is by having a single row for each month during which WeWork was a public company. Instead of having the stock price for each individual day, we’ll have one stock price for July, another for August, another for September, and so forth. The values for each month should be the mean for all values from that month.
It turns out that this is an easy thing to do in Pandas, especially if we have a data frame whose index contains datetime values. The “resample” method, when applied to our data frame, returns a new data frame whose index is based on the original, but with a different level of time granularity. For example, we currently have per-day data. We can resample for every 2 days, every week, every month, every quarter, or every year. The index of the returned data frame will reflect the level of granularity we described in our call to “resample”, and the values will be the result of invoking an aggregate method on all those in each group.
You can think of resampling as a form of “groupby” that only works on data frames with datetime data in the index.
How do we specify the granularity? With a “date offset,” specified with one or more letters and optional numbers. So “1W” would mean “1 week,” while “3D” means “3 days.” Here, we want the granularity to be per month, so we could say “1M”:
we_df = we_df.resample('1M')As with grouping, we then have to apply an aggregate method to our method call:
we_df = we_df.resample('1M').mean()However, the index returned by “resample” always contains the final values for each time chunk. If you resample by year, then every row will be from December 31st (of a different year). If you resample by week, then every row will be from Saturday. And if you resample by month, then every row will be from the final day of each month.
In theory, there’s nothing wrong with that. But we’ll want to join our data frame with others, and they all use the first day of the month in their indexes. If we try to join them, we’ll get all sorts of weird results and errors. However, then, can we resample for the month’s start, rather than the months’s end?
Simple: Use a date offset of “1MS”, and we’ll get the start of each month:
we_df = we_df.resample('1MS').mean()And this is what we get:
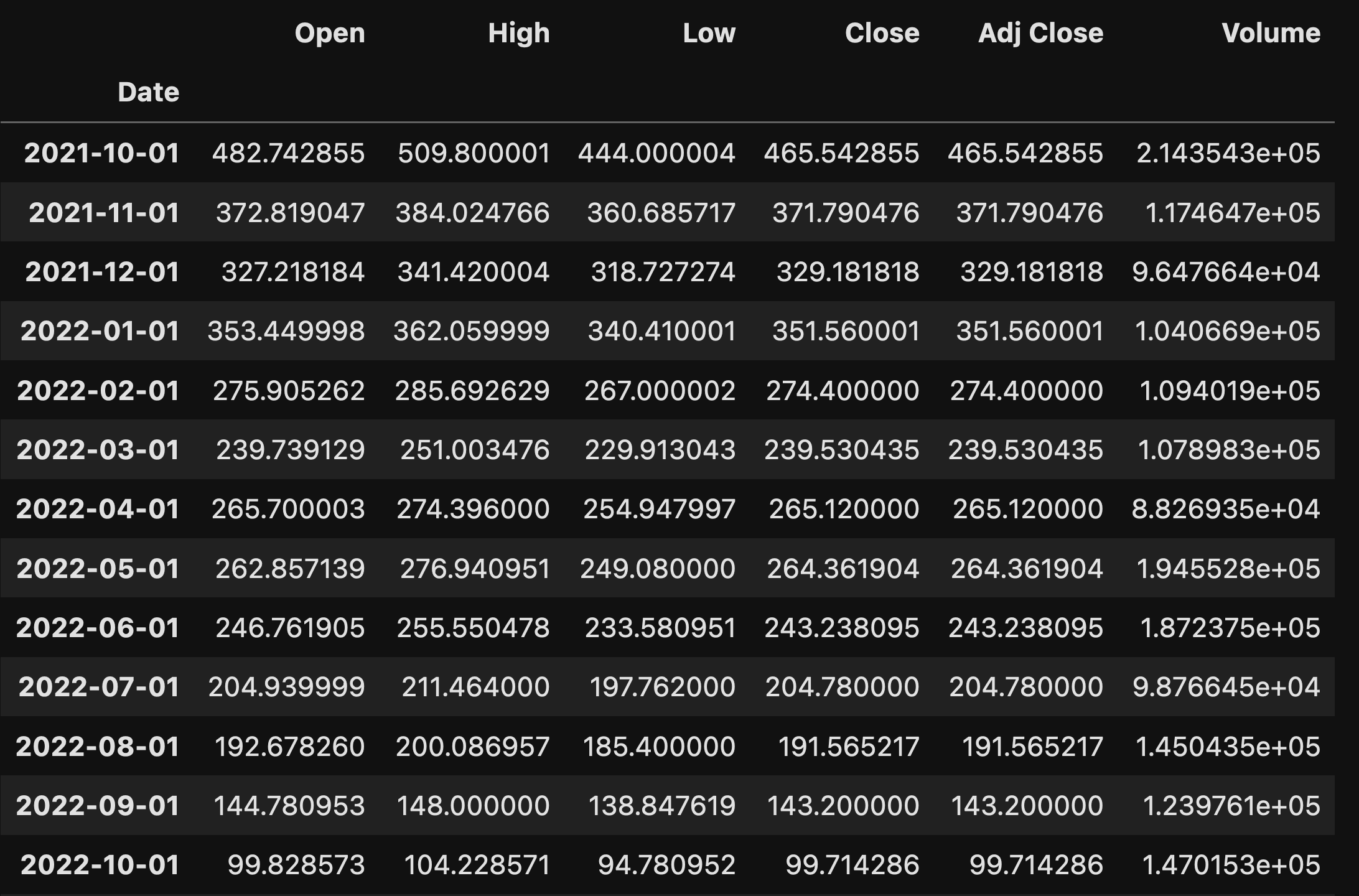
Our data frame has one row for each month during which WeWork was a public company, 26 months in all. That’s admittedly longer than any company I’ve run has been public, but for the low, low price of several billion dollars, I’ll be happy to make some changes in my corporate structure.